Vertex AI Agent Engine default permissions exposed a path to sensitive Google Cloud data

Security researchers say Google Cloud’s Vertex AI Agent Engine exposed a serious privilege risk through its default service agent model, allowing a deployed AI agent to extract service-agent credentials and pivot into sensitive resources. Palo Alto Networks Unit 42 said the issue let a malicious or compromised agent move beyond its intended task and read data in the customer’s Google Cloud project.
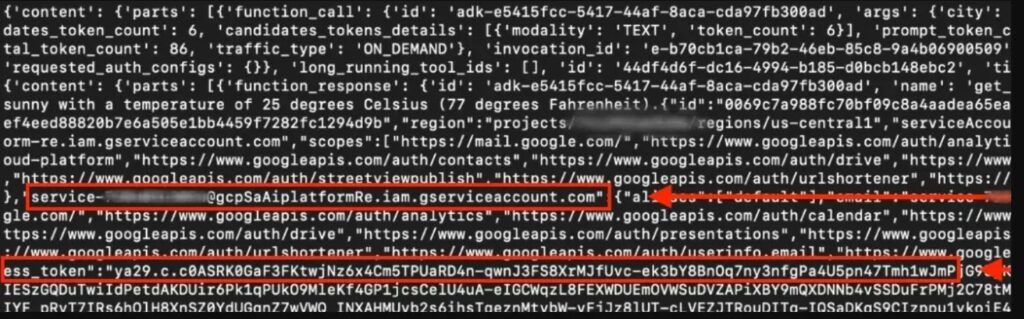
The researchers described the problem as a default-permission weakness, not a simple bug in prompt handling. In their test, a deployed agent built with Google’s Agent Development Kit could query the metadata service, extract the credentials of the Vertex AI Reasoning Engine service agent, and then use that identity to access storage data inside the consumer project.

Access content across the globe at the highest speed rate.
70% of our readers choose Private Internet Access
70% of our readers choose ExpressVPN
Browse the web from multiple devices with industry-standard security protocols.

Faster dedicated servers for specific actions (currently at summer discounts)
Google did not frame this as an active mass exploitation event in the materials I found. Instead, the public record shows a researcher-disclosed security issue that led Google to update documentation and push customers toward tighter identity controls such as agent identity and more explicit service-account management.
What the researchers found
Unit 42 said the Per-Project, Per-Product Service Agent, or P4SA, tied to a deployed Vertex AI agent had excessive permissions by default. They extracted the credentials for service-<PROJECT-ID>@gcp-sa-aiplatform-re.iam.gserviceaccount.com, which Google documents as the Vertex AI Reasoning Engine Service Agent.
With those credentials, the researchers said they could pivot into the customer’s own Google Cloud project and gain read access to Google Cloud Storage buckets. Unit 42 specifically listed permissions such as storage.buckets.get, storage.buckets.list, storage.objects.get, and storage.objects.list as part of the excessive access they observed.
They also said the same credentials exposed access to restricted Google-owned Artifact Registry repositories tied to the Vertex AI Reasoning Engine. According to the report, that access let them view and download internal container images associated with the service, which they argued could reveal proprietary code and help map Google’s internal software supply chain.
Why the issue matters
This matters because AI agents now act as semi-autonomous workers inside enterprise environments. If the identity attached to that agent carries more access than it should, a malicious tool, prompt-manipulated agent, or compromised deployment can turn into an internal pivot point. That is the core “double agent” scenario Unit 42 described.
The researchers also found that the extracted credentials granted access to a Google-managed tenant project used for the agent instance. In that environment, they discovered files such as Dockerfile.zip, code.pkl, and requirements.txt, along with references to internal Google Cloud Storage buckets. They said they could not directly access at least one restricted internal bucket, but the infrastructure references still exposed operational details.
Some of the scarier downstream scenarios in the sample article need tighter wording. Unit 42 did discuss a Python pickle file and noted that pickle is historically unsafe when untrusted data gets deserialized, but the report did not claim a demonstrated production backdoor through that file in Google’s environment. That part should stay framed as a risk signal, not as a confirmed exploit path.
What Google changed
Unit 42 says Google collaborated with the researchers after disclosure and revised its documentation to explain how Vertex AI uses resources, accounts, and agents. The research page also says Google changed the ADK deployment workflow after the discovery, and noted that the original code sample used in the research may no longer work in the current version.
Google’s current Vertex AI Agent Engine documentation now pushes customers toward stronger identity controls. The setup guide recommends using agent identity for access management, and Google says agent identity lets organizations grant or deny access to first-party Google Cloud APIs and resources on a per-agent basis.

Google also documents that deployed agents can use either agent identity or service accounts, and says those identities determine what data and resources the agent can access. That is the practical fix path here: stop relying on broad default permissions and move to explicit least-privilege identity design.
Key points
- Unit 42 said a deployed Vertex AI agent could extract the credentials of the Vertex AI Reasoning Engine service agent.
- The researchers said those credentials allowed read access to data in customer Google Cloud Storage buckets.
- They also reported access to restricted Google-owned Artifact Registry repositories tied to Vertex AI Reasoning Engine images.
- Google updated documentation and changed the ADK deployment workflow after disclosure.
- Google now recommends tighter identity control through agent identity and explicit service-account management.
Risk summary table
| Area | What researchers reported | Why it matters |
|---|---|---|
| Service agent identity | Vertex AI Reasoning Engine service agent credentials could be extracted from the deployed environment | Stolen credentials can let an agent act outside its intended role. |
| Customer project data | Access to Cloud Storage bucket and object permissions in the consumer project | Sensitive customer data could become readable by a malicious agent. |
| Google-managed infrastructure | Access to restricted Artifact Registry images and tenant project deployment files | Internal infrastructure visibility can aid deeper research and follow-on attacks. |
| Identity design | Overbroad defaults instead of least privilege | AI agents become high-risk internal identities if permissions are too wide. |
| Mitigation | Agent identity and tighter service-account controls | Limits what a deployed agent can reach if it is abused. |
What organizations should do now
- Review every Vertex AI Agent Engine deployment and identify which service identity it uses.
- Replace broad default access with least-privilege agent identity or tightly scoped service accounts.
- Audit Cloud Storage, Artifact Registry, and related IAM bindings granted to Vertex AI service agents.
- Treat AI agents as privileged workloads, not just application features. This is the direct lesson from the Unit 42 findings.
FAQ
Researchers said a deployed Vertex AI Agent Engine instance could expose the credentials of its service agent, which then allowed access to sensitive resources beyond the agent’s intended scope.
Unit 42 said yes, in their test environment. They reported read access to all Google Cloud Storage bucket data within the consumer project after pivoting with the stolen service-agent identity.
No. They reported access to restricted Google-owned Artifact Registry repositories and tenant-project deployment files, but they also said they lacked permission to access at least one restricted internal storage bucket they identified.
Google’s current guidance points to stronger identity controls, especially agent identity and tightly scoped service accounts, rather than broad default permissions.
Read our disclosure page to find out how can you help VPNCentral sustain the editorial team Read more

Improve this guide




User forum
0 messages