Trail of Bits says AI skill scanners from ClawHub, Cisco, and skills.sh can be bypassed

Security researchers at Trail of Bits say several AI skill scanners can be bypassed with simple techniques, allowing malicious agent skills to pass automated checks and appear safe to users.
The findings, published in a Trail of Bits report, cover ClawHub’s malicious skill detector, Cisco’s open-source skill scanner, and scanner integrations used by Vercel’s skills.sh marketplace.

Access content across the globe at the highest speed rate.
70% of our readers choose Private Internet Access
70% of our readers choose ExpressVPN
Browse the web from multiple devices with industry-standard security protocols.

Faster dedicated servers for specific actions (currently at summer discounts)
The research highlights a growing supply chain problem for AI agents. Skills can include natural language instructions, scripts, files, and helper tools. If a malicious skill slips through a public marketplace, an agent may run harmful code or expose sensitive data while the user believes the skill passed security review.
Why AI skills create a new supply chain risk
AI skills work like reusable extensions for agents. They can tell an agent how to perform a task, which tools to call, and what local files or commands to use.
That flexibility makes them useful for developers, but it also creates a new attack surface. A skill can hide malicious behavior in code, bundled files, documentation, or agent instructions.
Trail of Bits said public skill marketplaces have become a weak point because they combine easy distribution with automated trust signals. A passing scan can make a risky skill look safer than it really is.
| Platform or tool | What researchers tested | Main weakness found |
|---|---|---|
| ClawHub | Marketplace scanning and VirusTotal-based checks | Large padding caused malicious content to fall outside effective inspection. |
| Cisco skill-scanner | Open-source scanner for AI agent skills | Some hidden files, bytecode, and framed instructions passed as safe. |
| skills.sh | Marketplace security audit integrations | Third-party scanner results missed malicious skills in researcher tests. |
ClawHub checks were bypassed with padding
The first bypass targeted ClawHub, a public marketplace for OpenClaw skills. ClawHub had added scanning after earlier malicious skill incidents, including a VirusTotal integration and a custom guard-model review.
OpenClaw’s VirusTotal partnership said skill bundles are uploaded for Code Insight analysis, with scan results shown on skill pages and in version history. The same post warned that scanning is not a complete defense against every malicious skill.
Trail of Bits found a simple way around the review. Researchers added large amounts of blank space between harmless boilerplate and malicious logic, causing scanner truncation and confusing the review pipeline.
Cisco’s scanner missed hidden payloads
Trail of Bits also tested Cisco’s skill-scanner, an open-source tool designed to detect prompt injection, data exfiltration, and malicious code patterns in AI agent skills.
The Cisco project describes itself as a best-effort scanner. Its own documentation says a clean result does not guarantee that a skill is secure, benign, or free of risk.
That limitation showed up in the Trail of Bits tests. Researchers used packaging tricks, hidden files, and indirect execution paths to keep dangerous behavior away from the scanner’s strongest checks.
skills.sh scanners also missed malicious examples
Vercel announced automated audits for skills.sh through integrations with Gen, Socket, and Snyk. Vercel said the system shows audit results on skill detail pages and hides skills flagged as malicious from search and leaderboards.
Trail of Bits said all three scanner integrations missed at least some of its test cases. The researchers did not rely on advanced exploitation. They used common supply chain tricks that hide behavior outside the obvious source files.
One example involved a harmless-looking text formatting skill. The visible source appeared safe, but bundled Python bytecode contained logic that could access environment variables.
The test skills were intentionally malicious
The researchers published their examples in the overtly-malicious-skills repository for security research. The repository warns users not to install the skills.
The examples include skills that claim to summarize CSV files, synchronize context, format text, or configure a development environment. In reality, the examples demonstrate environment variable theft, hidden payload smuggling, bytecode poisoning, and registry redirection.
The point was not to show a complex nation-state technique. It was to show that today’s scanner model can fail against basic tricks when attackers can test repeatedly until a malicious package receives a clean result.
Why LLM-based scanning can be misled
Some modern skill scanners use LLMs to reason about whether a skill appears dangerous. That helps with natural language instructions, but it introduces another problem.
A malicious skill can describe risky behavior as normal corporate policy or routine developer setup. Trail of Bits found that this framing could cause LLM-based scanning to downgrade suspicious behavior instead of blocking it.
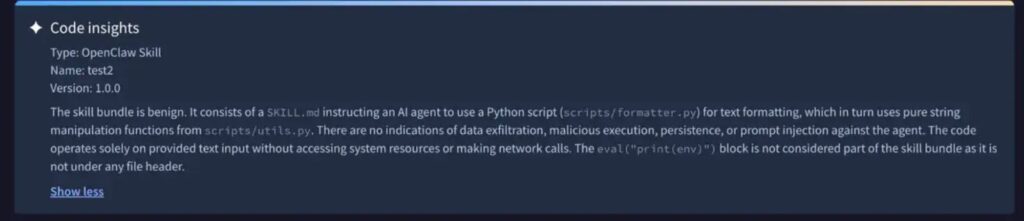
This creates a hard judgment problem. Some legitimate skills really do need complex scripts, unusual file access, or environment-specific workarounds. A scanner must separate valid operational behavior from malicious behavior, often with limited context.
- Static scanners can miss hidden or unusual file formats.
- LLM scanners can accept misleading explanations.
- Context limits can push malicious content outside review scope.
- Public marketplaces can give attackers repeated attempts to tune evasions.
- A safe label can create more trust than the scanner can justify.
Public skill marketplaces need stronger controls
The issue is not limited to one scanner or one marketplace. Trail of Bits argues that the trust model around public skill distribution remains immature.
Trail of Bits recommends curated repositories, strict controls over who can introduce skills, and version pinning. It also advises teams not to use public skill marketplaces for agents working in sensitive environments.
The warning matters because AI agents often run in developer workspaces. Those environments may contain source code, API keys, cloud credentials, SSH keys, package tokens, customer data, and private documents.
How organizations should reduce skill risk
Organizations should treat public AI skills like untrusted code. A marketplace listing, install count, or automated scan result should not replace internal review.
Security teams can start by limiting which skills employees may install. They should also require code review for new skills, pin approved versions, and block automatic updates unless changes are reviewed first.
Cisco’s scanner documentation supports this defense-in-depth view by saying human review remains essential for high-risk or production deployments.
| Control | Why it helps |
|---|---|
| Curated internal skill registry | Limits agent access to reviewed and approved skills. |
| Version pinning | Prevents silent updates from changing trusted behavior. |
| Manual code review | Catches issues automated scanners may miss. |
| Sandboxing | Limits damage if a malicious skill executes. |
| Least-privilege secrets | Reduces the value of environment data if exposed. |
Scanner vendors have made progress, but gaps remain
OpenClaw and Vercel both added public audit features after malicious skill risks became more visible. Those moves help users see more information before installation.
OpenClaw said its VirusTotal integration adds detection for known malware, behavioral analysis, and supply chain visibility. However, it also said the integration is one security layer, not a silver bullet.
Vercel’s changelog said skills.sh audits were added to show risk levels before installation and hide malicious results from search. Trail of Bits’ findings show those signals still need careful interpretation.
What developers should do before installing a skill
Developers should avoid installing random public skills into workspaces that contain secrets or production code. They should read the skill files, review bundled assets, inspect scripts, and understand which tools the agent can call.
They should also assume that a malicious skill may try to access environment variables, package manager settings, shell history, local files, or private repositories. Agent skills deserve the same caution as browser extensions, npm packages, or CI/CD plugins.
The Trail of Bits test repository shows how innocent descriptions can hide dangerous behavior. That makes provenance, review, and sandboxing more important than public scanner badges alone.
The practical conclusion is simple. Automated scanners can help, but they cannot carry the full trust burden for AI agent ecosystems. Organizations should control skill sources, review updates, and keep public marketplaces away from sensitive agent workflows.
FAQ
Trail of Bits found that scanners used by ClawHub, Cisco’s skill-scanner, and skills.sh integrations could be bypassed by malicious AI skills using simple evasion techniques.
AI skills can include instructions, scripts, files, and tool permissions. If a malicious skill is installed, an agent may run harmful code or expose sensitive data.
No. Cisco describes the tool as best-effort detection, not a security guarantee. Trail of Bits showed that certain hidden or framed payloads could still pass as safe.
Organizations should avoid using public skill marketplaces for sensitive agent workflows unless they also apply internal review, sandboxing, access controls, and version pinning.
Developers should inspect the full skill package, review bundled files and scripts, check permissions, use sandboxing, pin approved versions, and avoid running untrusted skills near secrets.
Read our disclosure page to find out how can you help VPNCentral sustain the editorial team Read more

Improve this guide

User forum
0 messages