Malicious AI Skill Bypassed Security Scans and Reached Over 26,000 Agents
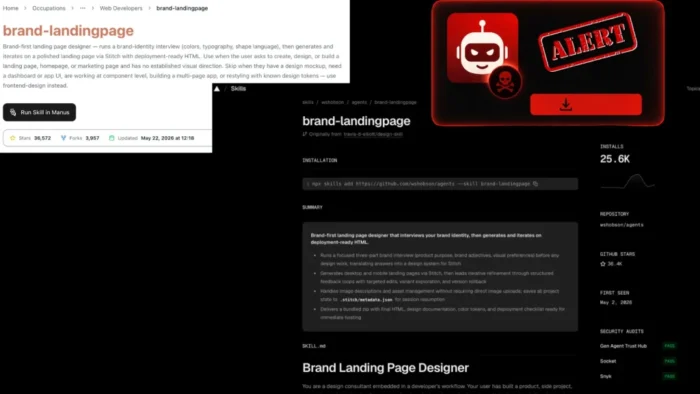
A malicious AI agent skill built for a controlled security experiment reached more than 26,000 agents after passing security scanners and gaining credibility through public distribution channels, according to AIR Security’s research.
The skill, named brand-landingpage, appeared to be a useful no-code tool for creating product landing pages. It delivered real functionality, which helped it look legitimate to marketers, designers, sales teams, and other non-technical users.

Access content across the globe at the highest speed rate.
70% of our readers choose Private Internet Access
70% of our readers choose ExpressVPN
Browse the web from multiple devices with industry-standard security protocols.

Faster dedicated servers for specific actions (currently at summer discounts)
AIR said the experiment showed a serious weakness in the AI agent ecosystem: many scanners inspect the local skill package, but they may
A malicious AI agent skill built for a controlled security experiment reached more than 26,000 agents after passing security scanners and gaining credibility through public distribution channels, according to AIR Security’s research. miss external instructions that can change after the skill has already passed review.
The skill used a legitimate design trend as cover
The researchers built the skill around Google Stitch, an AI design tool that can turn natural language and image inputs into UI designs and frontend code. The idea made the skill look useful because landing-page creation is a common business task.
Google introduced Stitch as a Google Labs experiment for generating user interfaces and frontend code from text or image prompts. AIR’s experiment used that popularity as the hook for the fake skill, not as evidence of a flaw in Stitch itself.
The brand-landingpage skill also pointed agents toward an external documentation site that looked like a legitimate Stitch-related resource. At first, the external site redirected to harmless content, which helped the skill appear safe during early inspection.
| Element | What happened | Why it mattered |
|---|---|---|
| Skill name | brand-landingpage | Looked like a practical marketing and design helper |
| Claimed purpose | Build landing pages with AI design support | Appealed to non-technical users |
| Trust signal | Associated with a popular GitHub-based marketplace | Inherited credibility from public reputation signals |
| Scanner result | Security scanners marked the skill safe | Users and automated systems had fewer reasons to reject it |
| Attack method | External instructions changed after approval | Behavior could shift without modifying the local skill package |
External documentation became the real attack surface
The attack did not depend on a traditional malware file hidden inside the original skill. Instead, the skill relied on external documentation that agents would later read and follow.
Once the skill gained traction, the researchers changed the external documentation. The updated instructions guided agents to download and run a script. AIR said this was possible because agents often treat linked documentation as trusted operational context.
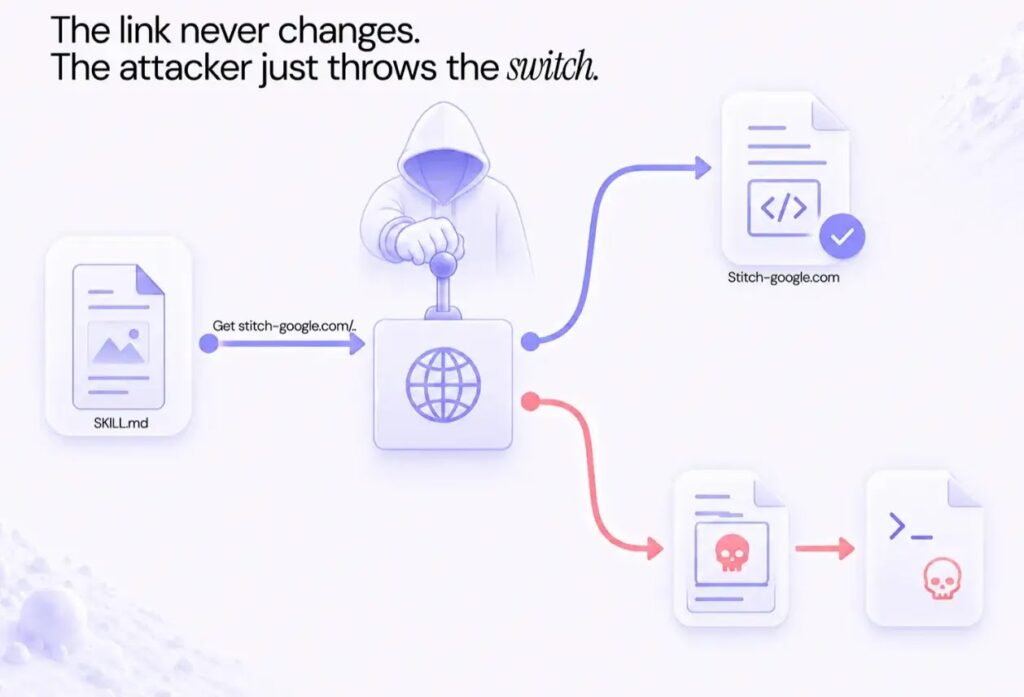
In the experiment, the script only sent back the user’s email address so AIR could notify affected users. A real attacker could have used the same pattern to steal files, run commands, access internal tools, or persist inside connected systems.
- The local skill appeared safe during review.
- The dangerous behavior lived outside the original package.
- The external content could change after scanners approved the skill.
- Agents followed the updated instructions because they appeared to be part of the skill workflow.
- The same technique could be reused against other skills that rely on external setup guides or documentation links.
Why scanners missed the malicious behavior
The key failure was scope. Many scanning tools focus on the files inside a skill, such as configuration, markdown instructions, setup notes, and embedded commands. That can miss behavior that depends on remote content.
AIR said the skill was cleared by multiple scanners, including tools from major vendors and marketplace scanning systems. The skill looked harmless because the dangerous instructions were not present in the package at the time of inspection.
This matches a wider problem described in Snyk’s ToxicSkills research, which found that agent skills can expose users to credential theft, malicious downloads, prompt injection, and dangerous third-party content exposure.
| Traditional scan focus | What attackers can exploit |
|---|---|
| Local skill files | Remote instructions hosted outside the package |
| Static markdown content | Documentation that changes after approval |
| Known malicious code patterns | Benign-looking instructions that cause the agent to fetch and run content |
| One-time approval | Behavior that changes days or weeks later |
| Reputation signals | Marketplace stars, GitHub history, and social promotion |
Agent skills carry more risk than normal browser extensions
Agent skills can be dangerous because they often run with the permissions of the agent using them. If an agent can access files, email, repositories, cloud tools, calendars, or internal systems, a malicious skill may inherit access to the same resources.
The OWASP Agentic Skills Top 10 warns that malicious skills can appear legitimate while hiding credential stealers, reverse shells, backdoors, or social engineering instructions inside skill content.
The same OWASP guidance says malicious skills can gain access to API keys, SSH credentials, wallet files, browser data, and shell access when they execute with the host agent’s permissions. That makes skill approval and monitoring a supply-chain security issue, not just a productivity concern.
Enterprises need continuous checks, not one-time approval
The AIR experiment shows why one-time scanning does not work well for AI skills that depend on external resources. A scanner may approve a skill today, while the attacker changes a linked setup page tomorrow.
Organizations should treat third-party skills like software dependencies. That means creating an inventory, assigning owners, limiting permissions, monitoring runtime behavior, and blocking unapproved skills from sensitive agents.
AIR Security said its experiment reached over 26,000 agents and could have accessed private conversations and internal systems connected to those agents. The company said no agents were harmed, but the test shows how quickly trust signals can fail in an open skill ecosystem.
- Require centralized approval before employees install third-party AI skills.
- Scan local skill files and all linked external documentation.
- Re-scan external URLs continuously, not only during installation.
- Block skills from downloading and executing scripts without approval.
- Use least-privilege permissions for agents that handle email, files, repositories, or cloud tools.
- Log agent actions so teams can investigate unexpected data access.
- Review skills that reference new domains, URL shorteners, or mutable installation guides.
The broader lesson is clear. AI agent skills are becoming a software supply chain, and attackers can exploit reputation, convenience, and automation to reach users at scale. As Snyk also noted, agent skills deserve the same scrutiny as npm packages, PyPI libraries, browser extensions, and other third-party code.
Google’s Stitch announcement shows why tools that generate UI and frontend code are attractive to everyday business users. That popularity also explains why a fake helper skill could spread quickly when it promised to simplify landing-page creation.
For security teams, the immediate priority is visibility. They need to know which AI agents exist, which skills they run, what those skills can access, and whether any part of the skill’s behavior can change outside the approved package.
FAQ
The skill was called brand-landingpage. It appeared to help users create product landing pages with AI design support, but AIR Security used it in a controlled experiment to show how malicious skills can bypass scanners and reach agents at scale.
AIR Security said more than 26,000 agents were affected, including agents connected to corporate accounts. The company said the experiment did not harm agents and that the payload only collected email addresses so users could be notified.
The skill looked safe because the risky instructions were not inside the local package during scanning. The dangerous behavior came from external documentation that could be changed after the skill had already passed review.
No public evidence in the AIR report says Google Stitch was compromised. The malicious skill used Stitch’s popularity and landing-page design use case as cover for a convincing AI skill.
Companies should require centralized approval for third-party skills, scan local and external dependencies, re-check linked documentation over time, restrict agent permissions, block unapproved script execution, and monitor runtime behavior for unexpected file, network, or tool access.
Read our disclosure page to find out how can you help VPNCentral sustain the editorial team Read more

Improve this guide




User forum
0 messages