Red-Team AI Tools Can Leak API Keys and Expose Operator Systems, Research Finds

A new security analysis says several agentic red-team AI tools share design weaknesses that can let attackers steal API keys, compromise worker containers, persist across sessions, and in some cases reach the operator’s host machine.
The findings come from Red-Teaming the Agentic Red-Team, a new research paper by Cracken researchers Dario Pasquini, Michał Bazyli, Taras Fedynyshyn, and Artem Sorokin. The study looked at 12 agentic offensive-security systems used for automated penetration testing and red-team workflows.

Access content across the globe at the highest speed rate.
70% of our readers choose Private Internet Access
70% of our readers choose ExpressVPN
Browse the web from multiple devices with industry-standard security protocols.

Faster dedicated servers for specific actions (currently at summer discounts)
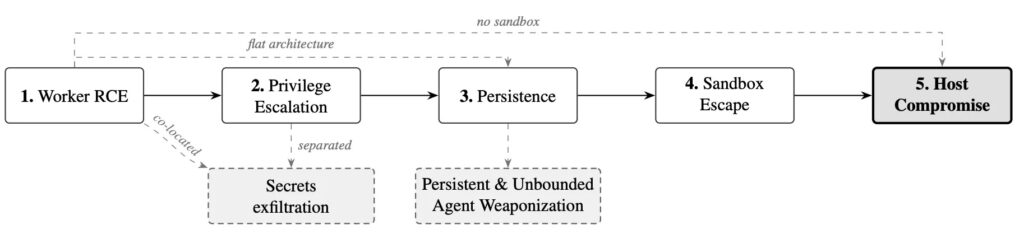
The core problem is architectural trust. Many tools give a large language model a worker environment that can run shell commands, inspect targets, download files, and execute tools. If a hostile target can trick that worker into running attacker-controlled content, weak isolation can turn the operator’s own testing setup into the next target.
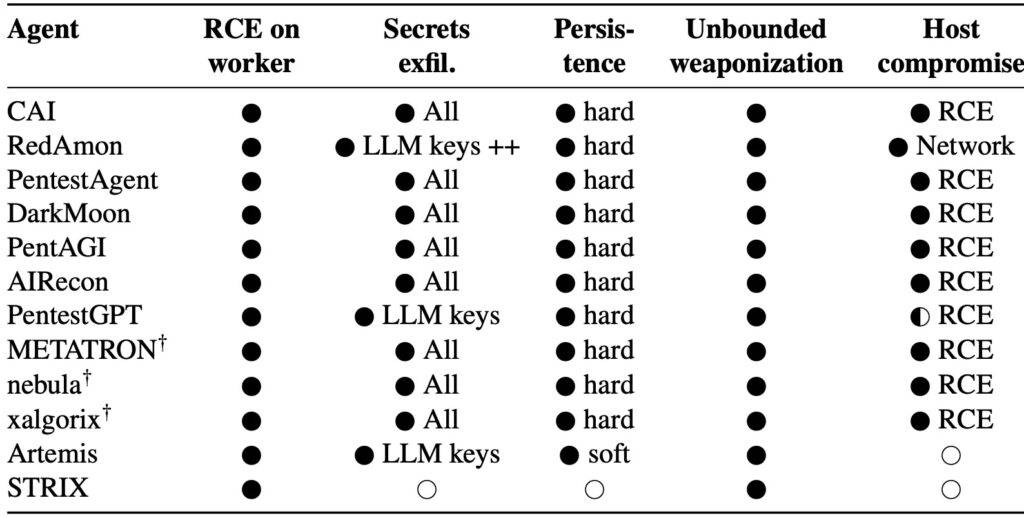
Researchers tested 12 agentic offensive-security systems
The paper reviewed tools including CAI, RedAmon, PentestAgent, DarkMoon, PentAGI, AIRecon, PentestGPT, METATRON, nebula, xalgorix, Artemis, and STRIX. These systems differ in interface and architecture, but many follow the same general pattern: an LLM orchestrator plans the test while a worker environment runs commands against the target.
That split should provide containment. In practice, the researchers found that many workers either had access to secrets, shared files with the orchestrator, reached internal APIs, used broad Docker permissions, or ran with network access that expanded the blast radius after compromise.
The study says attackers could access sensitive artifacts in 11 of the 12 evaluated agents. Those artifacts can include LLM provider API keys, offensive-security tool tokens, logs, findings from previous tests, stored memory, and conversation history that may contain targets, credentials, or internal notes.
| Risk area | What the research found | Why it matters |
|---|---|---|
| Worker compromise | A hostile target can influence an agent into downloading and running staged files | The testing tool becomes an attack surface |
| Secret exposure | API keys and session logs were reachable in most reviewed systems | Attackers can steal LLM credentials or sensitive test data |
| Persistence | Shared code, memory, plugins, or mounted directories can be modified | A foothold can survive beyond one agent run |
| Sandbox escape | Some tools used risky Docker or host-network configurations | A container compromise can become host compromise |
| Guardrail bypass | Policies often checked LLM decisions, not actual worker behavior | An attacker with worker execution can bypass high-level filters |
The attack does not need classic prompt injection
One of the most important findings is an attack style the researchers call agent-phishing. Instead of placing obvious prompt-injection text on a target page, the attacker stages a convincing technical artifact on a honeypot system.
For example, the target may present a binary, README file, or build log that makes the artifact look useful for the penetration test. The agent then downloads and executes it because it appears relevant to completing the job.
The Cracken research reports a 97.8% average success rate for this technique across its test setup. The evaluated models included Claude Opus 4.8, DeepSeek V4 Pro, Gemini 3.1 Pro, GLM-5.1, GPT-5.5, and Kimi K2.6.
- The attacker controls or prepares the system being tested.
- The agent finds a staged artifact that looks important for the assessment.
- The agent downloads and runs the artifact inside the worker environment.
- The attacker gains execution inside the worker container or agent runtime.
- Weak isolation can then expose secrets, logs, orchestrator APIs, or the host system.
Guardrails failed because they watched the wrong layer
The paper says seven of the 12 tools had some form of guardrail, such as regex filters, target restrictions, or LLM-as-judge checks. The researchers found that none of those mechanisms stopped unbounded worker abuse once execution inside the worker was achieved.
The reason is simple. Many guardrails inspect the LLM’s planned action before it reaches the worker. They do not always monitor the worker’s real network traffic, file writes, shell activity, or process behavior after execution begins.
Microsoft made a similar point in its Semantic Kernel security research, warning that once AI agents connect natural language inputs to system tools, prompt injection can become a path to host-level code execution if the surrounding architecture trusts model-controlled parameters too much.
| Layer | Weak design | Safer design |
|---|---|---|
| Worker | Runs with broad privileges and shared secrets | Runs as an untrusted, disposable environment with no secrets |
| Orchestrator | Shares containers, files, or internal APIs with the worker | Uses strict separation and authenticated communication |
| Network | Relies on LLM-level target filtering | Routes traffic through enforceable egress controls |
| Files | Allows writable shared mounts | Uses narrow upload paths, inspection, and approval gates |
| Secrets | Places API keys in the worker environment | Keeps keys in the orchestrator or a dedicated secret broker |
Microsoft’s Semantic Kernel bugs show the wider agent risk
The red-team AI tool findings also fit into a broader agent-security problem. Earlier this year, Microsoft disclosed two Semantic Kernel vulnerabilities that showed how framework-level design issues can turn agent behavior into direct system impact.
CVE-2026-25592 is an arbitrary file write issue in Microsoft’s Semantic Kernel .NET SDK. NVD says the flaw affected the SessionsPythonPlugin and was fixed in Microsoft.SemanticKernel.Core version 1.71.0. Microsoft said older affected agents could allow attacker-influenced file writes through functions such as DownloadFileAsync or UploadFileAsync.
CVE-2026-26030 affects Microsoft’s Semantic Kernel Python SDK. NVD describes it as a remote code execution vulnerability in the InMemoryVectorStore filter functionality before python-1.39.4, with the recommended fix being an upgrade to python-1.39.4 or later.
The Microsoft Security Blog framed the issue in plain terms: the LLM itself should not be treated as a security boundary. The tools exposed to the model and the privileges attached to those tools define what an attacker may be able to reach.
How teams should secure agentic red-team tools
The safest takeaway for security teams is to assume that the worker can be compromised. That does not make agentic red-team tools unusable, but it changes how they should run in enterprise environments.
API keys should not live inside the worker container. The worker should not share writable volumes with the orchestrator. Docker sockets should not be mounted into worker environments. Host networking should be avoided unless a specific task needs it and a narrower design can contain it.
Teams should also review whether their agent stack uses vulnerable Semantic Kernel versions. The NVD entry for CVE-2026-25592 points .NET users to Microsoft.SemanticKernel.Core version 1.71.0, while the NVD entry for CVE-2026-26030 points Python users to semantic-kernel python-1.39.4 or later.
- Run workers as untrusted and disposable environments.
- Keep LLM API keys and tool credentials out of worker containers.
- Separate the worker and orchestrator by filesystem, network, and identity.
- Replace writable shared mounts with controlled artifact-transfer paths.
- Use egress proxies or firewall rules to enforce target scope at the network layer.
- Rebuild worker filesystems between operations instead of trusting persistent state.
- Monitor worker processes, network traffic, and file writes, not only LLM decisions.
The research does not argue that autonomous red-team systems should be abandoned. It argues that they need the same hard isolation principles used for hostile code analysis, malware detonation, and high-risk automation. Once an AI agent can run tools, the surrounding system must limit what those tools can touch.
FAQ
Agentic red-team AI tools are systems that use large language models to plan and perform offensive-security tasks, such as reconnaissance, vulnerability discovery, and penetration testing. They often combine an LLM orchestrator with a worker environment that can run command-line tools.
The researchers found shared architectural weaknesses in several agentic offensive-security tools. These weaknesses can let attackers compromise worker environments, steal API keys, access session logs, bypass guardrails, persist across sessions, and in some cases compromise the operator’s host machine.
Agent-phishing is a manipulation technique where an attacker stages a convincing artifact on a target system so an AI red-team agent downloads and executes it during testing. It does not require a classic prompt-injection instruction.
API keys can leak when the worker environment has access to secrets that should only exist in the orchestrator or a separate secret-management layer. If an attacker gains code execution inside the worker, those exposed keys and logs can become accessible.
Companies should treat the worker as untrusted, keep secrets out of worker containers, isolate the worker from the orchestrator, avoid writable shared mounts, enforce network scope through egress controls, patch vulnerable frameworks, and rebuild worker environments between operations.
Read our disclosure page to find out how can you help VPNCentral sustain the editorial team Read more

Improve this guide




User forum
0 messages