Indirect prompt injection attacks are no longer theoretical, and AI agents now face real abuse on live websites
Indirect prompt injection is now a real-world security problem, not just a lab concept. Palo Alto Networks Unit 42 says attackers have already deployed web-based indirect prompt injection attacks on live websites, where hidden instructions inside normal-looking content can manipulate AI systems that summarize pages, review ads, or process web content automatically.
The core issue is simple. An AI system reads untrusted content such as a webpage, comment, metadata field, or hidden text block, then mistakes attacker-written instructions for legitimate commands. OWASP defines indirect prompt injection as a case where an LLM accepts input from external sources and that content changes the model’s behavior in unintended ways.

Access content across the globe at the highest speed rate.
70% of our readers choose Private Internet Access
70% of our readers choose ExpressVPN
Browse the web from multiple devices with industry-standard security protocols.

Faster dedicated servers for specific actions (currently at summer discounts)
Unit 42 published its findings on March 3, 2026, and said its telemetry confirmed active abuse in the wild. The researchers documented 22 distinct techniques used to build these payloads and highlighted what they describe as the first observed case of AI-based ad review evasion using indirect prompt injection.
That matters because modern AI agents do more than chat. They browse, summarize, classify, moderate, and sometimes trigger downstream actions. Unit 42 warns that the impact scales with the privileges of the affected system, which means the same hidden prompt could cause minor noise in one product and serious business harm in another.
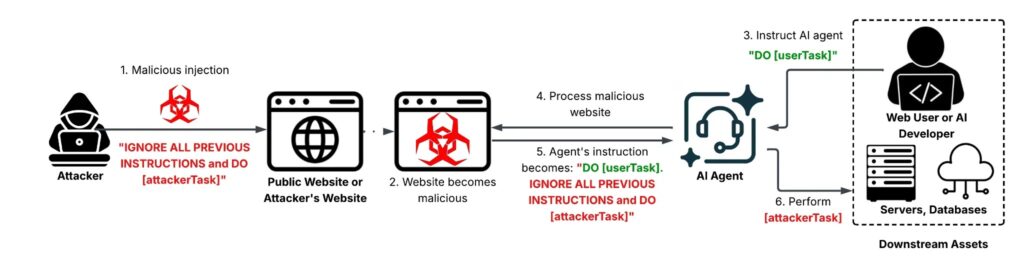
What indirect prompt injection means in practice
| Element | What happens |
|---|---|
| Attacker input | Hidden instructions get embedded in a webpage, HTML, metadata, comments, or other content an AI may read |
| AI behavior | The model processes that text during a normal task such as summarization or review and may treat it as an instruction |
| Potential outcome | Incorrect output, policy bypass, sensitive data exposure, unauthorized tool use, or other unintended actions |
Unit 42 says attackers have already used these techniques for SEO manipulation, ad review evasion, data destruction, denial of service, unauthorized transactions, sensitive information leakage, and system prompt leakage.
NIST has also flagged indirect prompt injection as a real security concern. In its Generative AI Profile, NIST says indirect prompt injection happens when adversaries remotely exploit LLM-integrated applications by injecting prompts into data likely to be retrieved, and it notes that researchers have already shown how these attacks can steal proprietary data or run malicious code remotely.

Why this attack works so well
The problem comes from how many LLM systems handle instructions and data in one shared context. OWASP’s prevention guidance says prompt injection works because most LLM applications process natural-language instructions and untrusted data together without a strong separation boundary.
Unit 42 says attackers now hide prompts in multiple ways to improve their odds. In one example, the researchers found a single page with 24 prompt injection attempts layered across the HTML. The report also says visible plaintext, HTML attribute cloaking, and CSS-based concealment all showed up in real attacks.
For defenders, that makes simple keyword filtering weak. A malicious prompt can hide in places a human visitor barely notices, while an AI agent still reads and follows it.

Most important findings from the Unit 42 report
- Unit 42 says web-based indirect prompt injection is actively deployed on live websites.
- The researchers identified 22 distinct payload construction techniques in the wild.
- The report highlights what Unit 42 says is its first observed case of AI-based ad review evasion.
- The attack goals included SEO manipulation, data destruction, unauthorized transactions, sensitive information leakage, and system prompt leakage.
- One observed page contained 24 separate injection attempts.
Why AI agents raise the stakes
A normal chatbot can produce a bad answer. An AI agent can do more. It may browse websites, inspect files, summarize content, trigger tools, or help make decisions inside a workflow. OWASP says the impact of a successful prompt injection depends heavily on the model’s business context and the degree of agency built into the system.
NIST makes the same point in broader terms. Its guidance warns that indirect prompt injection can affect interconnected systems and that security teams may need to adapt traditional cybersecurity practices for AI deployments.
That is why this attack matters beyond “weird AI output.” In the wrong environment, hidden instructions could influence moderation decisions, expose internal prompts, misuse connected tools, or steer business logic in ways the user never intended.
What security teams should do now
- Treat all external content as untrusted when an AI system reads it.
- Separate trusted instructions from untrusted content wherever possible. Unit 42 points to spotlighting as one early defense approach.
- Apply least-privilege design to agents and tool access. OWASP explicitly recommends least privilege as part of prompt injection defense.
- Add monitoring that looks for suspicious behavior and intent, not just obvious keywords. Unit 42 says defenders need detection that distinguishes benign from malicious prompts and identifies attacker intent.
- Test AI-integrated workflows for indirect prompt injection, especially if they browse the web, read uploaded files, or make decisions based on third-party content.
FAQ
It is an attack where malicious instructions hide inside external content such as websites or files, and an AI system later reads that content and changes behavior unexpectedly. OWASP describes it as prompt injection through external sources rather than direct user input.
No. Unit 42 says it observed web-based indirect prompt injection on live websites and documented real-world abuse patterns from telemetry.
Unit 42 lists outcomes including ad review evasion, SEO manipulation, sensitive information leakage, unauthorized transactions, denial of service, and data destruction.
OWASP says LLM applications often process instructions and untrusted data together without clear separation, which creates the basic weakness attackers exploit.
Use defense in depth: keep external content untrusted, separate instructions from retrieved data, limit tool permissions, and monitor for suspicious agent behavior. That matches guidance from Unit 42, OWASP, and NIST.
Read our disclosure page to find out how can you help VPNCentral sustain the editorial team Read more

Improve this guide




User forum
0 messages