Anthropic Says Claude Model Errors Were Resolved After June 5 Service Disruption

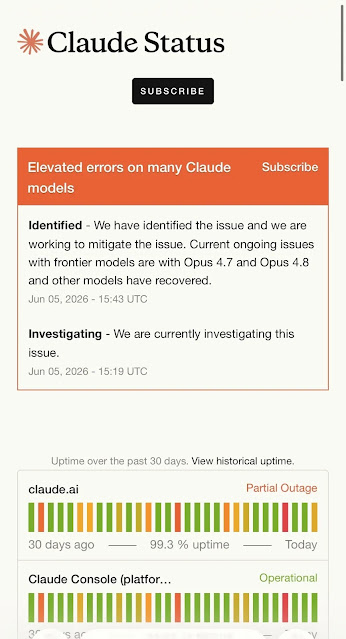
Anthropic resolved a June 5, 2026 service disruption that caused elevated errors across several Claude models, including Opus and Sonnet versions used by customers across Claude products and API workflows.
The official June 5 incident report says the problem began at 8:08 a.m. PT, or 15:08 UTC. Anthropic said success rates later returned to expected levels and confirmed that all affected models had fully recovered by 18:27 UTC.

Access content across the globe at the highest speed rate.
70% of our readers choose Private Internet Access
70% of our readers choose ExpressVPN
Browse the web from multiple devices with industry-standard security protocols.

Faster dedicated servers for specific actions (currently at summer discounts)
The incident did not appear as a security advisory. Anthropic’s report described elevated model errors and recovery status, but it did not say that customer data was exposed or that the disruption came from a breach.
Which Claude models were affected?
Anthropic’s status update listed a staggered recovery timeline across five models. Opus 4.6 recovered first at 15:25 UTC, followed by Sonnet 4.6 at 16:23 UTC.
Opus 4.8 recovered at 16:59 UTC, Opus 4.7 recovered at 17:12 UTC, and Opus 4.5 recovered at 17:29 UTC. The Claude incident page said all models had fully recovered by the final 18:27 UTC update.
The wording matters. The June 5 report names affected models, not every customer-facing Claude product. A separate June 2 incident affected claude.ai, Claude Console, Claude API, and Claude Code.
| Model | Recovery time |
|---|---|
| Claude Opus 4.6 | 15:25 UTC |
| Claude Sonnet 4.6 | 16:23 UTC |
| Claude Opus 4.8 | 16:59 UTC |
| Claude Opus 4.7 | 17:12 UTC |
| Claude Opus 4.5 | 17:29 UTC |
Claude services have seen repeated incidents in June
The broader Claude incident history shows multiple service degradations in early June. These included elevated errors for individual Opus and Sonnet models, plus a June 3 Claude Code service issue.
The June 2 outage had a wider listed component impact. Anthropic’s historical status entry said that incident affected claude.ai, Claude Console, Claude API, and Claude Code.
The public Claude status page also shows component-level availability over the past 90 days. At the time of review, it listed separate uptime figures for claude.ai, Claude Console, Claude API, Claude Code, Claude Cowork, and Claude for Government.
- The June 5 incident centered on elevated errors across many Claude models.
- Anthropic said all listed models recovered the same day.
- The official report did not name a customer data exposure event.
- The June 2 incident separately affected several Claude product components.
Why Claude outages matter for businesses
Claude has become part of daily workflows for developers, writers, analysts, support teams, and companies that use the Claude API in production tools. Even a short model degradation can delay coding tasks, automation jobs, customer support responses, internal research, and scheduled AI workflows.
For API customers, the main risk is operational. Requests can fail, time out, or return overloaded errors during service pressure. Anthropic’s API error documentation lists 500 as an internal API error, 504 as a timeout, and 529 as an overloaded error when the API is temporarily overloaded.
Teams that depend on Claude should treat these failures as expected conditions in production systems. That means handling errors cleanly, logging request IDs, retrying carefully, and avoiding designs that assume one AI provider will always respond immediately.
| Risk area | What can happen during degradation | Recommended control |
|---|---|---|
| API calls | Requests may fail or time out | Use retry logic, timeouts, and request logging |
| Developer workflows | Claude Code tasks may slow down or fail when dependent services degrade | Keep local fallback workflows available |
| Customer-facing AI features | End users may see delays or failed responses | Add fallback messages and graceful degradation |
| Business automation | Scheduled AI tasks may miss deadlines | Queue jobs and retry after recovery |
Recent Claude Code security issue is separate from the outage
The June 5 service disruption should not be confused with a separate Claude Code security vulnerability disclosed earlier this year. The GitHub advisory for GHSA-jh7p-qr78-84p7 describes a Claude Code project-load flaw that could leak Anthropic API keys before users confirmed trust in a repository.
That issue was tracked as CVE-2026-21852 and affected Claude Code versions before 2.0.65. The vulnerability involved malicious repository configuration, not Anthropic’s June 5 model availability incident.
The NVD entry says the flaw could expose Anthropic API keys when Claude Code opened an attacker-controlled repository with a malicious configuration that changed the ANTHROPIC_BASE_URL setting.
What API customers should do after the Claude disruption
Developers should review their Claude API integrations and make sure they handle temporary failures without breaking the rest of the application. This includes catching typed SDK errors, storing request IDs, and avoiding unlimited retries.
Anthropic’s Claude API error guide recommends using request IDs when contacting support and explains how timeout, overloaded, authentication, permission, and rate-limit errors appear.
Organizations should also decide what should happen when Claude is unavailable. Some use queues and delayed processing. Others route non-sensitive tasks to another model provider, pause automation, or show users a message that the AI feature is temporarily unavailable.
- Add exponential backoff for retryable API failures.
- Set sensible timeouts for user-facing requests.
- Log model name, status code, request ID, and timestamp.
- Queue non-urgent jobs instead of dropping them.
- Create fallback behavior for customer-facing AI features.
- Review whether critical workflows depend on a single model or provider.
Claude availability remains a reliability concern
The status history shows that Claude saw several model-specific incidents around the same period. That does not mean every incident had the same cause, but it does show why companies need resilience planning for AI systems.
The current Claude status dashboard remains the best official source for users checking whether claude.ai, Claude API, Claude Code, Claude Cowork, or Claude Console are degraded.
For Claude Code users, the separate GitHub security advisory is also worth reviewing because it explains the older project-load vulnerability and notes that version 2.0.65 patched the issue.
What companies should check next
Companies that use Claude in production should review uptime assumptions, incident runbooks, and user-facing error handling. AI outages can affect more than chat. They can disrupt coding tools, analytics workflows, support operations, and internal agents.
Security teams should also separate availability incidents from security incidents. A model outage does not automatically mean data exposure, but teams should still review logs around the affected window if their systems handled sensitive prompts or business-critical tasks.
Claude Code users who update manually should compare installed versions with the CVE-2026-21852 record and update to a fixed release if needed. That action addresses the earlier credential-leak vulnerability, not the June 5 service disruption.
FAQ
Anthropic reported elevated errors across many Claude models on June 5, 2026. The incident began at 15:08 UTC and Anthropic said all listed models had fully recovered by 18:27 UTC.
Anthropic listed Claude Opus 4.6, Sonnet 4.6, Opus 4.8, Opus 4.7, and Opus 4.5 in the June 5 recovery timeline.
Anthropic’s public June 5 incident report described elevated errors and model recovery times. It did not report customer data exposure or describe the event as a security breach.
Yes. Claude Code had a separate vulnerability tracked as CVE-2026-21852. It affected versions before 2.0.65 and could leak Anthropic API keys when opening a malicious repository before the trust prompt appeared.
Companies should add retry logic, timeouts, queueing, request logging, fallback user messages, and service monitoring. Critical workflows should not assume that one model or one AI provider will always be available.
Read our disclosure page to find out how can you help VPNCentral sustain the editorial team Read more

Improve this guide


User forum
0 messages