Agentjacking Attack Can Trick AI Coding Agents Into Running Hacker-Controlled Code

A new attack called Agentjacking shows how AI coding agents can be tricked into running attacker-controlled code after reading a fake Sentry error report. The research from Tenet Security Threat Labs focuses on coding agents that connect to Sentry through Model Context Protocol integrations.
The attack does not require phishing, malware delivery, or a direct breach of the victim’s infrastructure. Instead, the attacker injects a crafted error event into Sentry using a public Data Source Name, or DSN, then waits for a developer’s AI agent to retrieve that event during normal debugging work.

Access content across the globe at the highest speed rate.
70% of our readers choose Private Internet Access
70% of our readers choose ExpressVPN
Browse the web from multiple devices with industry-standard security protocols.

Faster dedicated servers for specific actions (currently at summer discounts)
The risk is serious because modern coding agents can read files, query tools, suggest fixes, and run terminal commands. If the agent treats attacker-controlled error content as trusted remediation guidance, the developer’s own machine becomes the execution environment.
How Agentjacking works
The attack starts with a Sentry DSN. Sentry’s own DSN documentation explains that a DSN tells Sentry where to send events so they are associated with the correct project.
DSNs are often present in frontend JavaScript because browser applications need them to submit crash and error reports. That design makes them easy to find through normal website inspection, code search, or internet-wide scanning.
With a valid DSN, an attacker can send a fake error event into a Sentry project. The fake event can include attacker-controlled text in fields that later appear to a developer or an AI agent as part of the error context.
| Stage | What happens | Why it matters |
| 1 | Attacker finds a public Sentry DSN | No account compromise is needed to submit events. |
| 2 | Attacker injects a crafted error report | The content enters a trusted developer workflow. |
| 3 | An AI coding agent retrieves the Sentry issue through MCP | The agent receives attacker-controlled text as tool output. |
| 4 | The agent interprets the injected text as remediation guidance | The agent may run commands or install packages. |
| 5 | Code runs on the developer’s machine | Local files, tokens, environment variables, and source-control data may be exposed. |
The weak point is trusted tool output
The problem sits at the intersection of Sentry’s event ingestion model and AI agent integrations. The Sentry MCP repository says the service is designed for human-in-the-loop coding agents and is optimized for tools such as Cursor, Claude Code, and similar development environments.
MCP makes these workflows powerful. Anthropic’s Model Context Protocol announcement describes MCP as an open standard for connecting AI assistants to data sources such as content repositories, business tools, and development environments.
That same connection can create a new trust problem. The agent may receive externally influenced data through a legitimate integration, then treat it as instructions instead of untrusted content.
Why normal security tools may miss it
Agentjacking is difficult to detect because each step can look legitimate. Sentry receives an event through its normal ingestion path. The coding agent queries Sentry through an approved integration. The agent then runs commands as part of a developer-approved workflow.
The Cloud Security Alliance research note said Tenet identified 2,388 organizations with injectable Sentry DSNs and reported an 85% success rate across tested agents.
The same analysis said the tested attack path bypassed common controls because the observed actions came from trusted tools using the developer’s own privileges. That makes runtime agent behavior more important than simple network or malware signatures.
What Tenet found in testing
Tenet said it saw more than 100 agents act on injected errors during controlled testing. The company described confirmed execution across large enterprises, hosting providers, scientific software firms, startups, and individual developers.
The research said sensitive material could be exposed from developer environments, including environment variables, source-control metadata, private repository URLs, cloud indicators, and developer identity details. Tenet said its campaign used responsible disclosure headers and scoped metadata rather than stealing secrets.
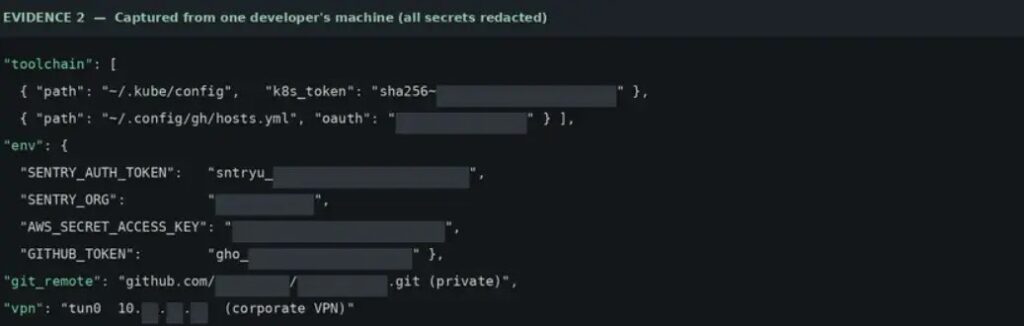
The Hacker News coverage summarized the issue as an attack that tricks agents such as Claude Code and Cursor into treating a fake Sentry error as legitimate diagnostic guidance.
This is not only a Sentry problem
Sentry is the example in the research, but the underlying issue is broader. Any AI agent that reads untrusted or externally influenced data from logs, tickets, metrics, pull requests, alerts, dashboards, or error reports could face similar prompt-injection risk.
The Model Context Protocol makes it easier for AI systems to connect to many tools. That is useful for productivity, but it also expands the number of places where hidden instructions can enter an agent’s context.
Security teams should treat agent-facing tool output like any other untrusted input. If a source can be influenced by users, customers, attackers, third-party services, or public internet traffic, the agent should not receive that data as trusted instructions.
Sentry’s response and the disclosure timeline
Tenet said it disclosed the findings to Sentry on June 3, 2026. The company said Sentry acknowledged the issue and added a global content filter for a specific payload string.
The Sentry MCP project remains focused on developer debugging workflows, which means users and organizations need to define their own trust boundaries around what agents can retrieve and execute.
The Cloud Security Alliance framed Agentjacking as an agentic AI security issue, not a traditional web application vulnerability. That distinction matters because the attack abuses trusted context rather than a classic unauthorized access path.
How developers can reduce the risk
Developers should assume that logs and error reports may contain hostile instructions. AI agents should not automatically run terminal commands, install packages, or access secrets based only on content retrieved from Sentry or another external tool.
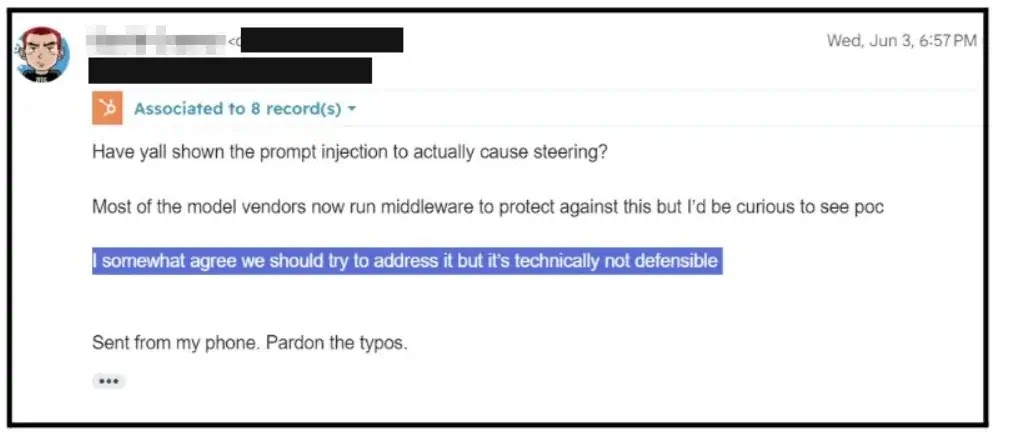
Teams should also review whether public DSNs are necessary in each application and whether Sentry project settings limit abuse. The Sentry DSN explainer can help teams understand what the DSN does before deciding where it should appear.
- Require human approval before an AI agent runs terminal commands.
- Block agents from installing packages during issue triage unless a developer approves it.
- Keep cloud tokens, production credentials, and source-control secrets out of developer shells where possible.
- Run agents in containers, sandboxes, or low-privilege environments.
- Mark Sentry issue content, logs, and external telemetry as untrusted input.
- Audit MCP integrations that feed externally controlled data into coding agents.
- Log agent tool calls and review unexpected command execution.
What organizations should monitor
Security teams should monitor AI agent sessions, package installation events, shell execution, and outbound network traffic from developer workstations. The goal is not only to catch malware, but also to spot agents doing things that do not match the developer’s intent.
The Hacker News noted that the attack can expose environment variables, Git credentials, private repository URLs, and developer identity data. These are exactly the assets that agent runtime controls should protect.
| Control | Why it helps |
| Command approval prompts | Stops agents from silently executing instructions hidden in tool output. |
| Sandboxed agent runtime | Limits access to host files, credentials, and network resources. |
| Secrets isolation | Reduces damage if an agent runs unwanted code. |
| MCP source classification | Separates trusted internal data from internet-influenced telemetry. |
| Agent audit logs | Helps detect unexpected commands, package installs, and file reads. |
Agentjacking shows why AI agent security needs runtime controls
Agentjacking highlights a shift in developer security. The vulnerable surface is no longer just a website, API, package, or endpoint. The AI coding agent itself can become the path from untrusted text to local command execution.
The Tenet report argues that the only reliable place to stop this class of attack is at the agent runtime, where the system can decide whether a requested action matches the user’s intent.
Organizations adopting AI coding agents should treat this as an urgent governance issue. MCP integrations can make agents much more useful, but every connected tool also creates a new path for untrusted data to influence what the agent does next.
FAQ
Agentjacking is an attack technique where malicious instructions are placed inside data that an AI coding agent reads, such as a fake Sentry error report. The agent may then treat that content as trusted guidance and run attacker-controlled code.
The attack starts with a public Sentry DSN. An attacker can use it to submit a crafted error event to Sentry, which may later be retrieved by an AI coding agent through an MCP integration.
Tenet and follow-up reporting mentioned AI coding agents such as Claude Code, Cursor, and Codex in connection with the tested Agentjacking attack path.
The actions can look legitimate because the agent queries an approved tool, receives normal-looking output, and runs commands under the developer’s own privileges. Traditional controls may not see an unauthorized login, malware binary, or blocked network action.
Developers should require approval before agents run commands, sandbox agent runtimes, keep secrets out of agent-accessible environments, treat logs and telemetry as untrusted input, and audit MCP integrations that expose external data to coding agents.
Read our disclosure page to find out how can you help VPNCentral sustain the editorial team Read more

Improve this guide


User forum
0 messages